Data Mining Materials with pymatgen and matminer#
Materials science is entering the data-driven era. With the rise of high-throughput density functional theory (DFT) calculations, massive datasets containing structural, electronic, and thermodynamic properties of materials are now publicly available. However, having big data is not enough, we need tools to:
Access this data programmatically.
Process, clean, and organize the data.
Extract useful features (“descriptors”) that represent material properties.
Use these features for machine learning models and materials discovery.
In this tutorial, we will go beyond simple querying and learn how to search for new semiconducting materials that are similar to a known compound.
We will start from the material that has been used in previous tutorials, \(\text{CaTiO}_3\), a perovskite-like structure, and follow this process:
Choose a neighboring transition metal to substitute for Ti — we will take V.
Use band gap constraints to ensure the candidates are semiconductors.
Search for materials with similar composition using:
Pymatgen + Materials Project
Matminer datasets
Compare results and discuss possible applications.
Step 1 - Setup and Installation#
First, make sure you have the required libraries installed:
!pip install mp-api matminer pymatgen
Requirement already satisfied: mp-api in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (0.45.8)
Requirement already satisfied: matminer in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (0.9.3)
Requirement already satisfied: pymatgen in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (2025.6.14)
Requirement already satisfied: setuptools in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from mp-api) (78.1.1)
Requirement already satisfied: msgpack in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from mp-api) (1.1.1)
Requirement already satisfied: maggma>=0.57.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from mp-api) (0.72.0)
Requirement already satisfied: typing-extensions>=3.7.4.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from mp-api) (4.15.0)
Requirement already satisfied: requests>=2.23.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from mp-api) (2.32.5)
Requirement already satisfied: monty>=2024.12.10 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from mp-api) (2025.3.3)
Requirement already satisfied: emmet-core>=0.84.3rc6 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from mp-api) (0.84.10rc2)
Requirement already satisfied: smart_open in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from mp-api) (7.3.0.post1)
Requirement already satisfied: numpy>=1.23 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matminer) (2.3.2)
Requirement already satisfied: pandas<3,>=1.5 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matminer) (2.3.2)
Requirement already satisfied: tqdm~=4.66 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matminer) (4.67.1)
Requirement already satisfied: pymongo~=4.5 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matminer) (4.10.1)
Requirement already satisfied: scikit-learn~=1.3 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matminer) (1.7.1)
Requirement already satisfied: sympy~=1.11 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matminer) (1.14.0)
Requirement already satisfied: python-dateutil>=2.8.2 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pandas<3,>=1.5->matminer) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pandas<3,>=1.5->matminer) (2025.2)
Requirement already satisfied: tzdata>=2022.7 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pandas<3,>=1.5->matminer) (2025.2)
Requirement already satisfied: dnspython<3.0.0,>=1.16.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pymongo~=4.5->matminer) (2.8.0)
Requirement already satisfied: charset_normalizer<4,>=2 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from requests>=2.23.0->mp-api) (3.4.3)
Requirement already satisfied: idna<4,>=2.5 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from requests>=2.23.0->mp-api) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from requests>=2.23.0->mp-api) (2.5.0)
Requirement already satisfied: certifi>=2017.4.17 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from requests>=2.23.0->mp-api) (2025.8.3)
Requirement already satisfied: scipy>=1.8.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from scikit-learn~=1.3->matminer) (1.16.1)
Requirement already satisfied: joblib>=1.2.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from scikit-learn~=1.3->matminer) (1.5.2)
Requirement already satisfied: threadpoolctl>=3.1.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from scikit-learn~=1.3->matminer) (3.6.0)
Requirement already satisfied: mpmath<1.4,>=1.1.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from sympy~=1.11->matminer) (1.3.0)
Requirement already satisfied: bibtexparser>=1.4.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pymatgen) (1.4.3)
Requirement already satisfied: matplotlib>=3.8 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pymatgen) (3.10.6)
Requirement already satisfied: networkx>=2.7 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pymatgen) (3.5)
Requirement already satisfied: orjson<4,>=3.10 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pymatgen) (3.11.3)
Requirement already satisfied: palettable>=3.3.3 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pymatgen) (3.3.3)
Requirement already satisfied: plotly>=5.0.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pymatgen) (6.3.0)
Requirement already satisfied: ruamel.yaml>=0.17.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pymatgen) (0.18.15)
Requirement already satisfied: spglib>=2.5 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pymatgen) (2.6.0)
Requirement already satisfied: tabulate>=0.9 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pymatgen) (0.9.0)
Requirement already satisfied: uncertainties>=3.1.4 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pymatgen) (3.2.3)
Requirement already satisfied: pyparsing>=2.0.3 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from bibtexparser>=1.4.0->pymatgen) (3.2.3)
Requirement already satisfied: pydantic>=2.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from emmet-core>=0.84.3rc6->mp-api) (2.11.7)
Requirement already satisfied: pydantic-settings>=2.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from emmet-core>=0.84.3rc6->mp-api) (2.10.1)
Requirement already satisfied: pymatgen-io-validation>=0.1.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from emmet-core>=0.84.3rc6->mp-api) (0.1.1)
Requirement already satisfied: pybtex~=0.24 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from emmet-core>=0.84.3rc6->mp-api) (0.25.1)
Requirement already satisfied: PyYAML>=3.01 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pybtex~=0.24->emmet-core>=0.84.3rc6->mp-api) (6.0.2)
Requirement already satisfied: latexcodec>=1.0.4 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pybtex~=0.24->emmet-core>=0.84.3rc6->mp-api) (3.0.1)
Requirement already satisfied: mongomock>=3.10.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from maggma>=0.57.1->mp-api) (4.3.0)
Requirement already satisfied: pydash>=4.1.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from maggma>=0.57.1->mp-api) (8.0.5)
Requirement already satisfied: jsonschema>=3.1.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from maggma>=0.57.1->mp-api) (4.25.1)
Requirement already satisfied: jsonlines>=4.0.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from maggma>=0.57.1->mp-api) (4.0.0)
Requirement already satisfied: aioitertools>=0.5.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from maggma>=0.57.1->mp-api) (0.12.0)
Requirement already satisfied: pyzmq>=25.1.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from maggma>=0.57.1->mp-api) (27.0.2)
Requirement already satisfied: sshtunnel>=0.1.5 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from maggma>=0.57.1->mp-api) (0.4.0)
Requirement already satisfied: boto3>=1.20.41 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from maggma>=0.57.1->mp-api) (1.40.25)
Requirement already satisfied: botocore<1.41.0,>=1.40.25 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from boto3>=1.20.41->maggma>=0.57.1->mp-api) (1.40.25)
Requirement already satisfied: jmespath<2.0.0,>=0.7.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from boto3>=1.20.41->maggma>=0.57.1->mp-api) (1.0.1)
Requirement already satisfied: s3transfer<0.14.0,>=0.13.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from boto3>=1.20.41->maggma>=0.57.1->mp-api) (0.13.1)
Requirement already satisfied: six>=1.5 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from python-dateutil>=2.8.2->pandas<3,>=1.5->matminer) (1.17.0)
Requirement already satisfied: attrs>=19.2.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from jsonlines>=4.0.0->maggma>=0.57.1->mp-api) (25.3.0)
Requirement already satisfied: jsonschema-specifications>=2023.03.6 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from jsonschema>=3.1.1->maggma>=0.57.1->mp-api) (2025.4.1)
Requirement already satisfied: referencing>=0.28.4 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from jsonschema>=3.1.1->maggma>=0.57.1->mp-api) (0.36.2)
Requirement already satisfied: rpds-py>=0.7.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from jsonschema>=3.1.1->maggma>=0.57.1->mp-api) (0.27.1)
Requirement already satisfied: contourpy>=1.0.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matplotlib>=3.8->pymatgen) (1.3.3)
Requirement already satisfied: cycler>=0.10 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matplotlib>=3.8->pymatgen) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matplotlib>=3.8->pymatgen) (4.59.2)
Requirement already satisfied: kiwisolver>=1.3.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matplotlib>=3.8->pymatgen) (1.4.9)
Requirement already satisfied: packaging>=20.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matplotlib>=3.8->pymatgen) (25.0)
Requirement already satisfied: pillow>=8 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from matplotlib>=3.8->pymatgen) (11.3.0)
Requirement already satisfied: sentinels in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from mongomock>=3.10.0->maggma>=0.57.1->mp-api) (1.1.1)
Requirement already satisfied: narwhals>=1.15.1 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from plotly>=5.0.0->pymatgen) (2.3.0)
Requirement already satisfied: annotated-types>=0.6.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pydantic>=2.0->emmet-core>=0.84.3rc6->mp-api) (0.7.0)
Requirement already satisfied: pydantic-core==2.33.2 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pydantic>=2.0->emmet-core>=0.84.3rc6->mp-api) (2.33.2)
Requirement already satisfied: typing-inspection>=0.4.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pydantic>=2.0->emmet-core>=0.84.3rc6->mp-api) (0.4.1)
Requirement already satisfied: python-dotenv>=0.21.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from pydantic-settings>=2.0->emmet-core>=0.84.3rc6->mp-api) (1.1.1)
Requirement already satisfied: ruamel.yaml.clib>=0.2.7 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from ruamel.yaml>=0.17.0->pymatgen) (0.2.12)
Requirement already satisfied: paramiko>=2.7.2 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from sshtunnel>=0.1.5->maggma>=0.57.1->mp-api) (4.0.0)
Requirement already satisfied: bcrypt>=3.2 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from paramiko>=2.7.2->sshtunnel>=0.1.5->maggma>=0.57.1->mp-api) (4.3.0)
Requirement already satisfied: cryptography>=3.3 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from paramiko>=2.7.2->sshtunnel>=0.1.5->maggma>=0.57.1->mp-api) (45.0.7)
Requirement already satisfied: invoke>=2.0 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from paramiko>=2.7.2->sshtunnel>=0.1.5->maggma>=0.57.1->mp-api) (2.2.0)
Requirement already satisfied: pynacl>=1.5 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from paramiko>=2.7.2->sshtunnel>=0.1.5->maggma>=0.57.1->mp-api) (1.5.0)
Requirement already satisfied: cffi>=1.14 in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from cryptography>=3.3->paramiko>=2.7.2->sshtunnel>=0.1.5->maggma>=0.57.1->mp-api) (1.17.1)
Requirement already satisfied: pycparser in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from cffi>=1.14->cryptography>=3.3->paramiko>=2.7.2->sshtunnel>=0.1.5->maggma>=0.57.1->mp-api) (2.22)
Requirement already satisfied: wrapt in /home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages (from smart_open->mp-api) (1.17.3)
import pandas as pd # to organize data
import matplotlib.pyplot as plt
import seaborn as sns # to visualize patterns and highlights
from mp_api.client import MPRester
from matminer.datasets import load_dataset
/home/paladin/anaconda3/envs/matdata/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Step 2 - Defining the Search Parameters#
Our base compound is \(\text{CaTiO}_3\). Suppose we are investigating its properties because it shows promise for a specific application, say, as a semiconducting material for solar energy harvesting.
However, we might run into a few real-world constraints:
Availability: Titanium may not be easily accessible or cost-effective in some regions.
Performance: There might exist similar compounds with better electronic properties.
Exploration: Sometimes, materials science is about looking for nearby alternatives that can surprise us.
To start our exploration, we’ll use a data-driven approach by querying the Materials Project database.
Choosing a Neighboring Transition Metal#
Looking at the Periodic Table, we notice that vanadium (V) sits right next to titanium (Ti) in the transition metals block. Neighboring elements often share similar electronic configurations, so replacing Ti with V in \(\text{CaTiO}_3\) could lead to structurally similar compounds — but with potentially different band gaps and properties.
Therefore, our new chemical system of interest is:
Calcium-Vanadium-Oxygen (Ca–V–O)
Focusing on Semiconductors#
Since we want to explore semiconductors for applications like photovoltaics, LEDs, or sensors, we’ll limit our search to materials with a band gap between \(1.1\) and \(3.2 \text{eV}\)
This range covers typical semiconductors, excluding metals (small/no band gap) and insulators (very large band gap).
In summary, our search parameters are:
Base compound: \(\text{CaTiO}_3\)
Neighboring transition metal: V (Titanium neighbor).
Band gap range: 1.1 – 3.2 eV (we want semiconductors).
Chemically similar systems: Calcium-Vanadium oxides (Ca-V-O).
Step 3 - Querying the Materials Project#
Connecting to the Materials Project#
Just as we did in the previous tutorial, we need to connect to the Materials Project to retrieve data by using our API key. For a detailed guide on how to obtain the key, please refer to the tutorial: Querying Materials.
Important
Remember: you should not share your API key with anyone.
We query the Materials Project database for Ca-V-O materials within the band gap range
# Replace YOUR_API_KEY_HERE with your Materials Project API key
API_KEY = "YOUR_API_KEY_HERE"
if API_KEY == "YOUR_API_KEY_HERE":
print("⚠️ Please replace 'YOUR_API_KEY_HERE' with your Materials Project API key.")
mpr = None
else:
mpr = MPRester(API_KEY)
print("✅ MPRester initialized successfully!")
⚠️ Please replace 'YOUR_API_KEY_HERE' with your Materials Project API key.
# Search parameters
bandgap_min = 1.1
bandgap_max = 3.2
chemsys = "Ca-V-O" # Searching for CaVO3 and similar oxides
# Query Materials Project for Ca-V-O semiconductors
results_mp = mpr.materials.summary.search(
chemsys=chemsys,
band_gap=(bandgap_min, bandgap_max),
fields=["material_id", "formula_pretty", "band_gap",
"formation_energy_per_atom", "density", "symmetry"]
)
df_mp = pd.DataFrame([
{
"material_id": r.material_id,
"formula": r.formula_pretty,
"band_gap": r.band_gap,
"formation_energy_per_atom": r.formation_energy_per_atom,
"density": r.density,
"crystal_system": r.symmetry.crystal_system
}
for r in results_mp
])
# Sort by band gap for better readability
df_mp = df_mp.sort_values(by="band_gap").reset_index(drop=True)
df_mp
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[5], line 2
1 # Query Materials Project for Ca-V-O semiconductors
----> 2 results_mp = mpr.materials.summary.search(
3 chemsys=chemsys,
4 band_gap=(bandgap_min, bandgap_max),
5 fields=["material_id", "formula_pretty", "band_gap",
6 "formation_energy_per_atom", "density", "symmetry"]
7 )
9 df_mp = pd.DataFrame([
10 {
11 "material_id": r.material_id,
(...) 18 for r in results_mp
19 ])
21 # Sort by band gap for better readability
AttributeError: 'NoneType' object has no attribute 'materials'
Step 4 - Exploring the Results#
After retrieving our dataset from the Materials Project, the next step is to explore it visually. Tables of numbers are useful, but they can be overwhelming — plots often reveal patterns and insights much more quickly.
Histogram: distribution of band gaps#
One property we are especially interested in is the band gap, since it determines whether a material behaves as a conductor, semiconductor, or insulator. Recall that we set our search range to 1.1–3.2 eV because we are specifically targeting semiconductors.
To better understand how the band gaps of our retrieved materials are distributed, let’s make a histogram. This plot will show us how many of the Ca–V–O compounds fall into different band gap ranges.
plt.figure(figsize=(8, 5))
sns.histplot(df_mp["band_gap"], bins=10, kde=True)
plt.xlabel("Band Gap (eV)")
plt.ylabel("Count")
plt.title("Distribution of Band Gaps for Ca-V-O Materials (Materials Project)")
plt.show()
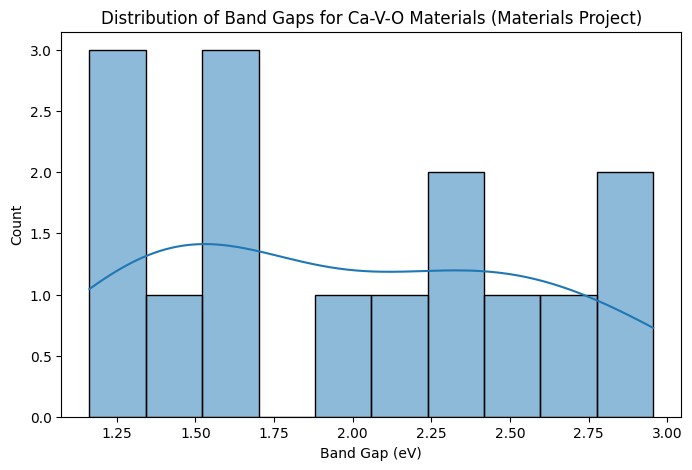
The histogram gives us a distribution of band gaps for all the candidate materials in our search. Each bar represents the number of materials with a band gap in a certain range, and the smooth line (kernel density estimate) helps us see the overall shape of the distribution.
By inspecting this plot, we can quickly answer questions such as:
Do most of the Ca–V–O compounds cluster around a narrow band gap range, or are they spread out?
Are there enough candidates with band gaps close to the ideal semiconductor values (e.g., ~1.5–2.0 eV for solar cell applications)?
Are there any outliers with unusually high or low band gaps compared to the rest?
This kind of exploratory visualization helps us narrow down which materials may be most promising for further study, without having to examine each entry individually.
Scatter Plot: Band Gap vs. Formation Energy#
Formation energy per atom tells us how stable a material is — lower (more negative) values generally mean more stable compounds. Plotting formation energy against band gap helps us identify candidates that are both stable and in the desired band gap range.
plt.figure(figsize=(8, 6))
sns.scatterplot(
data=df_mp,
x="band_gap",
y="formation_energy_per_atom",
hue="crystal_system",
s=100,
palette="Set2"
)
plt.axvline(1.1, color="red", linestyle="--", label="Lower band gap limit")
plt.axvline(3.2, color="red", linestyle="--", label="Upper band gap limit")
plt.xlabel("Band Gap (eV)")
plt.ylabel("Formation Energy per Atom (eV)")
plt.title("Band Gap vs. Formation Energy (Ca-V-O Materials)")
plt.legend()
plt.show()
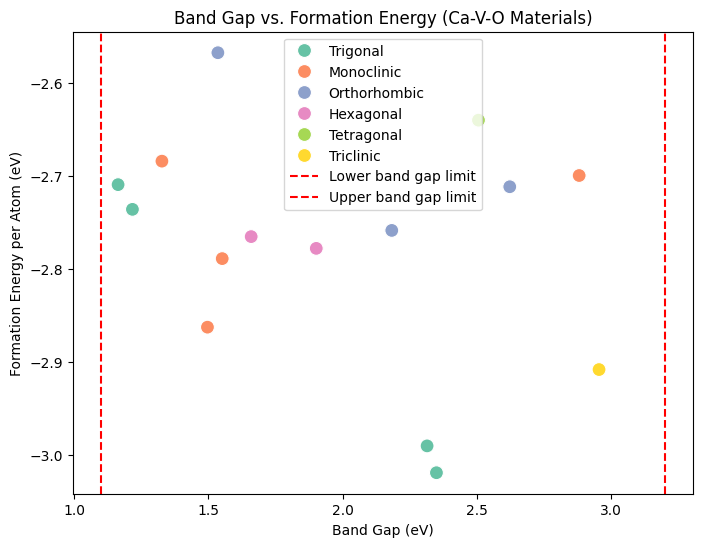
Tip
Points further down (more negative formation energy) represent more stable compounds.
The vertical dashed lines mark our chosen semiconductor band gap window.
By looking at the points within this window, we can spot which candidates are both semiconducting and stable, making them more attractive for real applications.
Density Distribution by Crystal System#
Another interesting angle is to check if different crystal systems tend to have different densities. This can be useful for practical applications, where density affects properties like mass transport, mechanical strength, and cost.
plt.figure(figsize=(8, 6))
sns.boxplot(
data=df_mp,
x="crystal_system",
y="density"
)
plt.xlabel("Crystal System")
plt.ylabel("Density (g/cm³)")
plt.title("Density Distribution of Ca-V-O Materials by Crystal System")
plt.xticks(rotation=45)
plt.show()
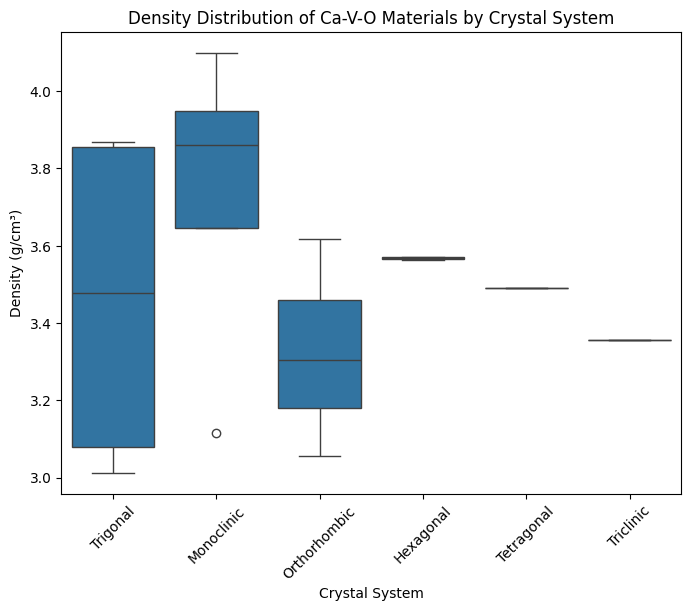
Tip
Each box summarizes the density distribution for a given crystal system.
This allows us to see whether certain crystal families (e.g., monoclinic vs. orthorhombic) tend to be lighter or denser.
If a specific application (say, lightweight materials for aerospace) requires low density, this view can guide which crystal systems deserve more attention.
Step 5 - Using Matminer Datasets#
The matminer library provides curated datasets ready for materials informatics. If you want to learn more about the datasets available in matminer, you can visit their website here. It is a very complete page that indicates the names and the content of the datasets, in addition to the number of entries of each dataset. This information will be essential when choosing which dataset might be useful for our wanted criteria. In our example, we are working with perovskites and a limited bandgap, so we will load matminer datasets that contain this information.
We can also check the list using code, as follows:
from matminer.datasets import get_available_datasets
# List all datasets available
datasets = get_available_datasets()
print(datasets)
boltztrap_mp: Effective mass and thermoelectric properties of 8924 compounds in The Materials Project database that are calculated by the BoltzTraP software package run on the GGA-PBE or GGA+U density functional theory calculation results. The properties are reported at the temperature of 300 Kelvin and the carrier concentration of 1e18 1/cm3.
brgoch_superhard_training: 2574 materials used for training regressors that predict shear and bulk modulus.
castelli_perovskites: 18,928 perovskites generated with ABX combinatorics, calculating gllbsc band gap and pbe structure, and also reporting absolute band edge positions and heat of formation.
citrine_thermal_conductivity: Thermal conductivity of 872 compounds measured experimentally and retrieved from Citrine database from various references. The reported values are measured at various temperatures of which 295 are at room temperature.
dielectric_constant: 1,056 structures with dielectric properties, calculated with DFPT-PBE.
double_perovskites_gap: Band gap of 1306 double perovskites (a_1-b_1-a_2-b_2-O6) calculated using Gritsenko, van Leeuwen, van Lenthe and Baerends potential (gllbsc) in GPAW.
double_perovskites_gap_lumo: Supplementary lumo data of 55 atoms for the double_perovskites_gap dataset.
elastic_tensor_2015: 1,181 structures with elastic properties calculated with DFT-PBE.
expt_formation_enthalpy: Experimental formation enthalpies for inorganic compounds, collected from years of calorimetric experiments. There are 1,276 entries in this dataset, mostly binary compounds. Matching mpids or oqmdids as well as the DFT-computed formation energies are also added (if any).
expt_formation_enthalpy_kingsbury: Dataset containing experimental standard formation enthalpies for solids. Formation enthalpies were compiled primarily from Kim et al., Kubaschewski, and the NIST JANAF tables (see references). Elements, liquids, and gases were excluded. Data were deduplicated such that each material is associated with a single formation enthalpy value. Refer to Wang et al. (see references) for a complete desciption of the methods used. Materials Project database IDs (mp-ids) were assigned to materials from among computed materials in the Materials Project database (version 2021.03.22) that were 1) not marked 'theoretical', 2) had structures matching at least one ICSD material, and 3) were within 200 meV of the DFT-computed stable energy hull (e_above_hull < 0.2 eV). Among these candidates, we chose the mp-id with the lowest e_above_hull that matched the reported spacegroup (where available).
expt_gap: Experimental band gap of 6354 inorganic semiconductors.
expt_gap_kingsbury: Identical to the matbench_expt_gap dataset, except that Materials Project database IDs (mp-ids) have been associated with each material using the same method as described for the expt_formation_enthalpy_kingsbury dataset. Columns have also been renamed for consistency with the formation enthalpy data.
flla: 3938 structures and computed formation energies from "Crystal Structure Representations for Machine Learning Models of Formation Energies."
glass_binary: Metallic glass formation data for binary alloys, collected from various experimental techniques such as melt-spinning or mechanical alloying. This dataset covers all compositions with an interval of 5 at. % in 59 binary systems, containing a total of 5959 alloys in the dataset. The target property of this dataset is the glass forming ability (GFA), i.e. whether the composition can form monolithic glass or not, which is either 1 for glass forming or 0 for non-full glass forming.
glass_binary_v2: Identical to glass_binary dataset, but with duplicate entries merged. If there was a disagreement in gfa when merging the class was defaulted to 1.
glass_ternary_hipt: Metallic glass formation dataset for ternary alloys, collected from the high-throughput sputtering experiments measuring whether it is possible to form a glass using sputtering. The hipt experimental data are of the Co-Fe-Zr, Co-Ti-Zr, Co-V-Zr and Fe-Ti-Nb ternary systems.
glass_ternary_landolt: Metallic glass formation dataset for ternary alloys, collected from the "Nonequilibrium Phase Diagrams of Ternary Amorphous Alloys,’ a volume of the Landolt– Börnstein collection. This dataset contains experimental measurements of whether it is possible to form a glass using a variety of processing techniques at thousands of compositions from hundreds of ternary systems. The processing techniques are designated in the "processing" column. There are originally 7191 experiments in this dataset, will be reduced to 6203 after deduplicated, and will be further reduced to 6118 if combining multiple data for one composition. There are originally 6780 melt-spinning experiments in this dataset, will be reduced to 5800 if deduplicated, and will be further reduced to 5736 if combining multiple experimental data for one composition.
heusler_magnetic: 1153 Heusler alloys with DFT-calculated magnetic and electronic properties. The 1153 alloys include 576 full, 449 half and 128 inverse Heusler alloys. The data are extracted and cleaned (including de-duplicating) from Citrine.
jarvis_dft_2d: Various properties of 636 2D materials computed with the OptB88vdW and TBmBJ functionals taken from the JARVIS DFT database.
jarvis_dft_3d: Various properties of 25,923 bulk materials computed with the OptB88vdW and TBmBJ functionals taken from the JARVIS DFT database.
jarvis_ml_dft_training: Various properties of 24,759 bulk and 2D materials computed with the OptB88vdW and TBmBJ functionals taken from the JARVIS DFT database.
m2ax: Elastic properties of 223 stable M2AX compounds from "A comprehensive survey of M2AX phase elastic properties" by Cover et al. Calculations are PAW PW91.
matbench_dielectric: Matbench v0.1 test dataset for predicting refractive index from structure. Adapted from Materials Project database. Removed entries having a formation energy (or energy above the convex hull) more than 150meV and those having refractive indices less than 1 and those containing noble gases. Retrieved April 2, 2019. For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_expt_gap: Matbench v0.1 test dataset for predicting experimental band gap from composition alone. Retrieved from Zhuo et al. supplementary information. Deduplicated according to composition, removing compositions with reported band gaps spanning more than a 0.1eV range; remaining compositions were assigned values based on the closest experimental value to the mean experimental value for that composition among all reports. For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_expt_is_metal: Matbench v0.1 test dataset for classifying metallicity from composition alone. Retrieved from Zhuo et al. supplementary information. Deduplicated according to composition, ensuring no conflicting reports were entered for any compositions (i.e., no reported compositions were both metal and nonmetal). For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_glass: Matbench v0.1 test dataset for predicting full bulk metallic glass formation ability from chemical formula. Retrieved from "Nonequilibrium Phase Diagrams of Ternary Amorphous Alloys,’ a volume of the Landolt– Börnstein collection. Deduplicated according to composition, ensuring no compositions were reported as both GFA and not GFA (i.e., all reports agreed on the classification designation). For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_jdft2d: Matbench v0.1 test dataset for predicting exfoliation energies from crystal structure (computed with the OptB88vdW and TBmBJ functionals). Adapted from the JARVIS DFT database. For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_log_gvrh: Matbench v0.1 test dataset for predicting DFT log10 VRH-average shear modulus from structure. Adapted from Materials Project database. Removed entries having a formation energy (or energy above the convex hull) more than 150meV and those having negative G_Voigt, G_Reuss, G_VRH, K_Voigt, K_Reuss, or K_VRH and those failing G_Reuss <= G_VRH <= G_Voigt or K_Reuss <= K_VRH <= K_Voigt and those containing noble gases. Retrieved April 2, 2019. For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_log_kvrh: Matbench v0.1 test dataset for predicting DFT log10 VRH-average bulk modulus from structure. Adapted from Materials Project database. Removed entries having a formation energy (or energy above the convex hull) more than 150meV and those having negative G_Voigt, G_Reuss, G_VRH, K_Voigt, K_Reuss, or K_VRH and those failing G_Reuss <= G_VRH <= G_Voigt or K_Reuss <= K_VRH <= K_Voigt and those containing noble gases. Retrieved April 2, 2019. For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_mp_e_form: Matbench v0.1 test dataset for predicting DFT formation energy from structure. Adapted from Materials Project database. Removed entries having formation energy more than 2.5eV and those containing noble gases. Retrieved April 2, 2019. For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_mp_gap: Matbench v0.1 test dataset for predicting DFT PBE band gap from structure. Adapted from Materials Project database. Removed entries having a formation energy (or energy above the convex hull) more than 150meV and those containing noble gases. Retrieved April 2, 2019. For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_mp_is_metal: Matbench v0.1 test dataset for predicting DFT metallicity from structure. Adapted from Materials Project database. Removed entries having a formation energy (or energy above the convex hull) more than 150meV and those containing noble gases. Retrieved April 2, 2019. For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_perovskites: Matbench v0.1 test dataset for predicting formation energy from crystal structure. Adapted from an original dataset generated by Castelli et al. For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_phonons: Matbench v0.1 test dataset for predicting vibration properties from crystal structure. Original data retrieved from Petretto et al. Original calculations done via ABINIT in the harmonic approximation based on density functional perturbation theory. Removed entries having a formation energy (or energy above the convex hull) more than 150meV. For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
matbench_steels: Matbench v0.1 test dataset for predicting steel yield strengths from chemical composition alone. Retrieved from Citrine informatics. Deduplicated. For benchmarking w/ nested cross validation, the order of the dataset must be identical to the retrieved data; refer to the Automatminer/Matbench publication for more details.
mp_all_20181018: A complete copy of the Materials Project database as of 10/18/2018. mp_all files contain structure data for each material while mp_nostruct does not.
mp_nostruct_20181018: A complete copy of the Materials Project database as of 10/18/2018. mp_all files contain structure data for each material while mp_nostruct does not.
phonon_dielectric_mp: Phonon (lattice/atoms vibrations) and dielectric properties of 1296 compounds computed via ABINIT software package in the harmonic approximation based on density functional perturbation theory.
piezoelectric_tensor: 941 structures with piezoelectric properties, calculated with DFT-PBE.
ricci_boltztrap_mp_tabular: Ab-initio electronic transport database for inorganic materials. Complex multivariable BoltzTraP simulation data is condensed down into tabular form of two main motifs: average eigenvalues at set moderate carrier concentrations and temperatures, and optimal values among all carrier concentrations and temperatures within certain ranges. Here are reported the average of the eigenvalues of conductivity effective mass (mₑᶜᵒⁿᵈ), the Seebeck coefficient (S), the conductivity (σ), the electronic thermal conductivity (κₑ), and the Power Factor (PF) at a doping level of 10¹⁸ cm⁻³ and at a temperature of 300 K for n- and p-type. Also, the maximum values for S, σ, PF, and the minimum value for κₑ chosen among the temperatures [100, 1300] K, the doping levels [10¹⁶, 10²¹] cm⁻³, and doping types are reported. The properties that depend on the relaxation time are reported divided by the constant value 10⁻¹⁴. The average of the eigenvalues for all the properties at all the temperatures, doping levels, and doping types are reported in the tables for each entry. Data is indexed by materials project id (mpid)
steel_strength: 312 steels with experimental yield strength and ultimate tensile strength, extracted and cleaned (including de-duplicating) from Citrine.
superconductivity2018: Dataset of ~16,000 experimental superconductivity records (critical temperatures) from Stanev et al., originally from the Japanese National Institute for Materials Science. Does not include structural data. Includes ~300 measurements from materials found without superconductivity (Tc=0). No modifications were made to the core dataset, aside from basic file type change to json for (un)packaging with matminer. Reproduced under the Creative Commons 4.0 license, which can be found here: http://creativecommons.org/licenses/by/4.0/.
tholander_nitrides: A challenging data set for quantum machine learning containing a diverse set of 12.8k polymorphs in the Zn-Ti-N, Zn-Zr-N and Zn-Hf-N chemical systems. The phase diagrams of the Ti-Zn-N, Zr-Zn-N, and Hf-Zn-N systems are determined using large-scale high-throughput density functional calculations (DFT-GGA) (PBE). In total 12,815 relaxed structures are shared alongside their energy calculated using the VASP DFT code. The High-Throughput Toolkit was used to manage the calculations. Data adapted and deduplicated from the original data on Zenodo at https://zenodo.org/record/5530535#.YjJ3ZhDMJLQ, published under MIT licence. Collated from separate files of chemical systems and deduplicated according to identical structures matching ht_ids. Prepared in collaboration with Rhys Goodall.
ucsb_thermoelectrics: Database of ~1,100 experimental thermoelectric materials from UCSB aggregated from 108 source publications and personal communications. Downloaded from Citrine. Source UCSB webpage is http://www.mrl.ucsb.edu:8080/datamine/thermoelectric.jsp. See reference for more information on original data aggregation. No duplicate entries are present, but each src may result in multiple measurements of the same materials' properties at different temperatures or conditions.
wolverton_oxides: 4,914 perovskite oxides containing composition data, lattice constants, and formation + vacancy formation energies. All perovskites are of the form ABO3. Adapted from a dataset presented by Emery and Wolverton.
['boltztrap_mp', 'brgoch_superhard_training', 'castelli_perovskites', 'citrine_thermal_conductivity', 'dielectric_constant', 'double_perovskites_gap', 'double_perovskites_gap_lumo', 'elastic_tensor_2015', 'expt_formation_enthalpy', 'expt_formation_enthalpy_kingsbury', 'expt_gap', 'expt_gap_kingsbury', 'flla', 'glass_binary', 'glass_binary_v2', 'glass_ternary_hipt', 'glass_ternary_landolt', 'heusler_magnetic', 'jarvis_dft_2d', 'jarvis_dft_3d', 'jarvis_ml_dft_training', 'm2ax', 'matbench_dielectric', 'matbench_expt_gap', 'matbench_expt_is_metal', 'matbench_glass', 'matbench_jdft2d', 'matbench_log_gvrh', 'matbench_log_kvrh', 'matbench_mp_e_form', 'matbench_mp_gap', 'matbench_mp_is_metal', 'matbench_perovskites', 'matbench_phonons', 'matbench_steels', 'mp_all_20181018', 'mp_nostruct_20181018', 'phonon_dielectric_mp', 'piezoelectric_tensor', 'ricci_boltztrap_mp_tabular', 'steel_strength', 'superconductivity2018', 'tholander_nitrides', 'ucsb_thermoelectrics', 'wolverton_oxides']
Here, we can identify datasets that are relevant to our study. Some potentially useful ones are:
castelli_perovskites
double_perovskites_gap
wolverton_oxides
Loading a Dataset from Matminer#
We start by importing and loading the three datasets that seemed most promising:
from matminer.datasets import load_dataset
# Candidate datasets
df_castelli = load_dataset("castelli_perovskites")
df_double = load_dataset("double_perovskites_gap")
df_wolverton = load_dataset("wolverton_oxides")
# Quick overview
print("Castelli Perovskites:", df_castelli.shape, df_castelli.columns)
print("Double Perovskites:", df_double.shape, df_double.columns)
print("Wolverton Oxides:", df_wolverton.shape, df_wolverton.columns)
Castelli Perovskites: (18928, 10) Index(['fermi level', 'fermi width', 'e_form', 'gap is direct', 'structure',
'mu_b', 'formula', 'vbm', 'cbm', 'gap gllbsc'],
dtype='object')
Double Perovskites: (1306, 6) Index(['formula', 'a_1', 'b_1', 'a_2', 'b_2', 'gap gllbsc'], dtype='object')
Wolverton Oxides: (4914, 16) Index(['formula', 'atom a', 'atom b', 'lowest distortion', 'e_form', 'e_hull',
'mu_b', 'vpa', 'gap pbe', 'a', 'b', 'c', 'alpha', 'beta', 'gamma',
'e_form oxygen'],
dtype='object')
Step 6 - Assessing Dataset Suitability#
Not all datasets are equally useful for our specific purpose (analyzing band gaps). We will check their columns.
We see that the property that is relevant to us right now (band gap) appears in each of the datasets as a column. For castellli_perovskites and double_perovskites_gap the column is gap gllbsc. For wolverton_oxides it is gap pbe
print("Castelli band gap summary:")
print(df_castelli["gap gllbsc"].describe())
print("\nDouble Perovskites band gap summary:")
print(df_double["gap gllbsc"].describe())
print("\nWolverton Oxides band gap summary:")
print(df_wolverton["gap pbe"].describe())
Castelli band gap summary:
count 18928.000000
mean 0.070813
std 0.459684
min 0.000000
25% 0.000000
50% 0.000000
75% 0.000000
max 7.000000
Name: gap gllbsc, dtype: float64
Double Perovskites band gap summary:
count 1306.000000
mean 4.012035
std 1.581775
min 0.106620
25% 2.786297
50% 4.074557
75% 5.090252
max 8.343255
Name: gap gllbsc, dtype: float64
Wolverton Oxides band gap summary:
count 4914.000000
mean 0.360123
std 0.902904
min 0.000000
25% 0.000000
50% 0.000000
75% 0.000000
max 6.221000
Name: gap pbe, dtype: float64
Findings:#
Castelli Perovskites
The gap pbe column seems to be almost entirely zero.
This means it cannot be used to analyze band gaps.
Still useful for other properties, but not suitable for our current task.
Double Perovskites (gap dataset)
Contains a valid gap pbe column.
Good candidate for band gap exploration.
Wolverton Oxides
Also contains a column with mostly zero values.
Important
This evaluation step is crucial: before doing any analysis, we must ensure the dataset actually contains meaningful data for the property of interest.
For our assessment, we will continue with double_perovskites_gap.
df_double.head()
| formula | a_1 | b_1 | a_2 | b_2 | gap gllbsc | |
|---|---|---|---|---|---|---|
| 0 | AgNbLaAlO6 | Ag | Nb | La | Al | 4.164543 |
| 1 | AgNbLaGaO6 | Ag | Nb | La | Ga | 4.454629 |
| 2 | AgNbLaInO6 | Ag | Nb | La | In | 4.192522 |
| 3 | AgNbMgTiO6 | Ag | Nb | Mg | Ti | 3.963857 |
| 4 | AgNbSnTiO6 | Ag | Nb | Sn | Ti | 2.881239 |
Step 7 - Filtering the Dataset#
Now that we have chosen a suitable dataset, we are going to filter out to narrow our results closer to what we are looking for:
Restrict the bandgap range to semiconductors (1.1-3.2 eV).
Filter by formula to focus on Ca-containing oxides, and then of those results, only the ones containing V.
# Apply band gap filter
gap_min, gap_max = 1.1, 3.2
df_double_filtered = df_double[(df_double["gap gllbsc"] >= gap_min) &
(df_double["gap gllbsc"] <= gap_max)]
# Further filter: only Ca-containing compounds
df_double_filtered = df_double_filtered[df_double_filtered["formula"].str.contains("Ca", na=False)]
df_double_filtered = df_double_filtered[df_double_filtered["formula"].str.contains("V", na=False)]
print("Double Perovskites (filtered):", df_double_filtered.shape)
Double Perovskites (filtered): (17, 6)
We can see that the dataset got reduced from 1306 to 17 entries.
Comparing Band Gap distributions#
Once our datasets are filtered to a comparables scope (same band gap range, Ca-V based compounds), we can finally place them side by side. This will show us the differences using different data sources for our analysis:
Materials project query: a targeted search we designed ourselves (Ca-V-O only). It reflects very specific chemistry and electronic criteria.
Matminer datasets: pre-curated collections from the literature. Even after filtering, they reflect different sampling strategies and levels of completeness.
By comparing distributions, we can ask:
Do the curated datasets reproduce trends similar to a direct query from the Materials Project?
Are there systematic differences (e.g., broader or narrower band gap ranges)?
How does dataset choice influence the materials we might consider for applications?
This is important because in real research, your conclusions may depend on the data source you rely on.
We use a Kernel Density Estimate (KDE) plot to overlay the band gap distributions. This smooth curve allows us to see not just raw counts, but the overall shape of the distribution for each dataset.
plt.figure(figsize=(10,6))
sns.kdeplot(df_mp["band_gap"], label="MP Query (Ca-V-O)", fill=True, alpha=0.4)
sns.kdeplot(df_double_filtered["gap gllbsc"], label="Double Perovskites", fill=True, alpha=0.4)
plt.xlabel("Band Gap (eV)")
plt.ylabel("Density")
plt.title("Band Gap Distributions Across Different Sources")
plt.legend()
plt.show()
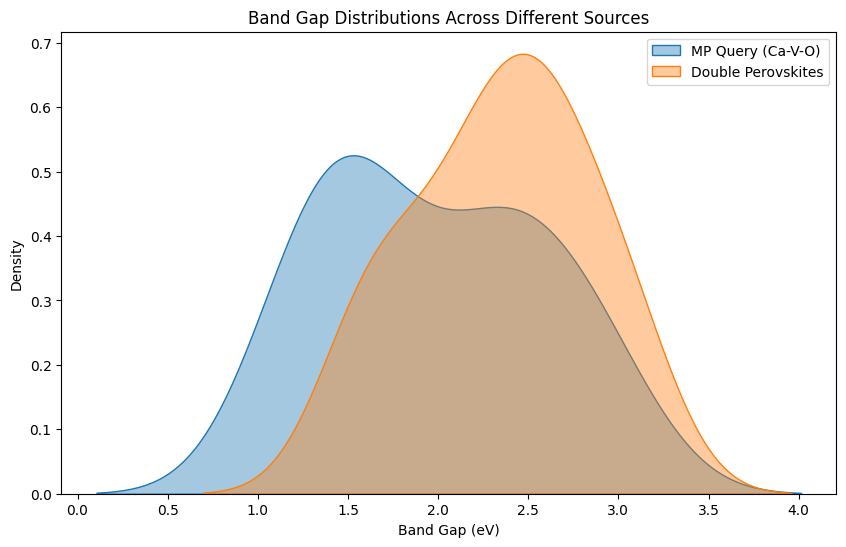
Tip
Pay attention to:
Peaks in the distributions: indicate “common” band gaps for the given chemistry and dataset.
Shifts between datasets: can reveal methodological or sampling differences (e.g., if one dataset is consistently lower/higher).
Spread of the curves: tells us whether a dataset captures a wide variety of materials or only a narrow subset.
Step 8 - Reflecting on the Filtered Matminer Results#
We would like to have an idea of the materials that we obtained from our filtering process with matminer too:
df_double_filtered
| formula | a_1 | b_1 | a_2 | b_2 | gap gllbsc | |
|---|---|---|---|---|---|---|
| 207 | CaHfCsVO6 | Ca | Hf | Cs | V | 2.234428 |
| 219 | CaHfLiVO6 | Ca | Hf | Li | V | 2.939416 |
| 225 | CaHfNaVO6 | Ca | Hf | Na | V | 2.576283 |
| 275 | CaZrCsVO6 | Ca | Zr | Cs | V | 2.604377 |
| 288 | CaZrLiVO6 | Ca | Zr | Li | V | 3.120800 |
| 294 | CaZrNaVO6 | Ca | Zr | Na | V | 2.457279 |
| 390 | CsVCaGeO6 | Cs | V | Ca | Ge | 1.540581 |
| 392 | CsVCaSnO6 | Cs | V | Ca | Sn | 1.797516 |
| 393 | CsVCaTiO6 | Cs | V | Ca | Ti | 2.424147 |
| 750 | LiVCaGeO6 | Li | V | Ca | Ge | 2.638234 |
| 751 | LiVCaSiO6 | Li | V | Ca | Si | 1.748631 |
| 752 | LiVCaSnO6 | Li | V | Ca | Sn | 2.241717 |
| 753 | LiVCaTiO6 | Li | V | Ca | Ti | 3.037880 |
| 877 | NaVCaGeO6 | Na | V | Ca | Ge | 2.040411 |
| 878 | NaVCaSiO6 | Na | V | Ca | Si | 1.556374 |
| 879 | NaVCaSnO6 | Na | V | Ca | Sn | 2.198836 |
| 880 | NaVCaTiO6 | Na | V | Ca | Ti | 2.748176 |
After applying our filters (Ca + V + semiconductor band gap range), we obtained a set of candidate materials from the Matminer datasets. At first glance, their chemical formulas look different from the ones we retrieved directly from the Materials Project.
Why is that?
Materials Project query gave us simple ternary oxides (Ca–V–O), as we explicitly defined the chemical system.
Matminer datasets (like double_perovskites_gap) contain double perovskites, which are more complex by design. This means the filtered results include Ca, V, and O, but also additional elements.
So, while both datasets respect our filters, they represent different chemical spaces:
Materials Project: minimal chemical system, narrow and well-controlled.
Matminer: richer perovskite family, where our chosen elements coexist with others.
Important
In data mining, it’s not just about what you filter, but also about where the data comes from.
The MP results might be more directly comparable to our base compound (\(\text{CaTiO}_3\)).
The Matminer results, however, open doors to more exploratory searches, where V is embedded in larger families of perovskite structures.
Step 9 - Wrapping up#
We have now completed our journey through a meaningful example of data mining in materials science. Let’s briefly reflect on the path we followed and what we learned along the way:
What we did#
Defined a scientific question: exploring alternatives to \(\text{CaTiO}_3\) by substituting Ti with V while keeping an eye on semiconducting behavior.
Used the Materials Project: we learned how to query a live database with specific parameters (composition + band gap range), and explored the returned materials through organized dataframes and visualizations.
Analyzed distributions: plots helped us quickly see trends in band gaps, densities, and crystal systems.
Explored curated datasets with Matminer: we experimented with external datasets like double_perovskites_gap and wolverton_oxides, and discovered how dataset design shapes the results we obtain.
Reflected on data sources: we learned that the same filter criteria can yield very different sets of candidate materials, depending on whether the dataset focuses on simple oxides, perovskites, or other families.
Key takeaways#
Data mining is contextual: knowing your dataset is as important as knowing your filters.
Visualization is powerful: simple plots can reveal trends and guide decisions.
Different databases complement each other: Materials Project provides up-to-date calculations, while Matminer offers curated, task-specific datasets that enable broader explorations.
Future Challenges#
This tutorial provided only a first look at how materials data mining works. Here are some directions for further exploration:
Try substituting other transition metals (e.g., Nb, Cr, Fe) and compare trends.
Extend the workflow by adding stability checks (e.g., energy above hull from Materials Project).
Apply machine learning tools from Matminer to predict band gaps or other properties.
Connect this workflow with ASE to automatically build and manipulate structures for deeper analysis.